
We’ve become some what of a friendly neighborhood AI lab around HuggingFace and OLlama
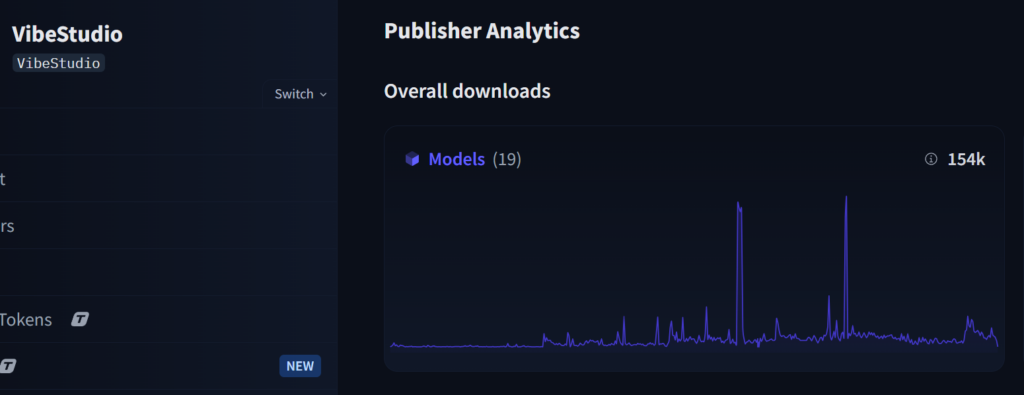
150k+ downloads and counting.
Initially we were only fine-tuning SOTA models with our meagre compute with the intention of acclimating ourselves with the latest AI architectures and recipes. We did not anticipate our models would suddenly have a demand. We did what we could and gave back to the community from where we benefit a lot.
Then we picked up a REAP pruned model by Cerebras. We were blown away by what they had done. They had gone far ahead of the EAN paper they stated was their inspiration. We wanted to test the waters and have at it. We didn’t want to add to the noise so we chose a model no one had pruned yet.
We were given compute by our incubator ITEL (Immersive Technology & Entrepreneurship Labs) founded by Padma Shri Ashok Jhunjhunwala with Reema as CEO. An 8 X H200 cluster from E2E – India’s most affordable AI data center. (Their shares are publicly listed, you should check out their stock price)
We improved upon EAN and REAP pruning methods by adding our own research methodology – which actually came out of the frugality that we only had one cluster and can’t run parallel experiments so every iteration had to count. We called this THRIFT. More tech details are in the whitepaper which you can download here.
What did the community say?
When it comes to AI model launching, there are two places we can consider a litmus test whether the model is innovative or slop. Thankfully we started getting a whole lot of downloads, quants and finetunes done organically by the community and they in tern got thousands of downloads.
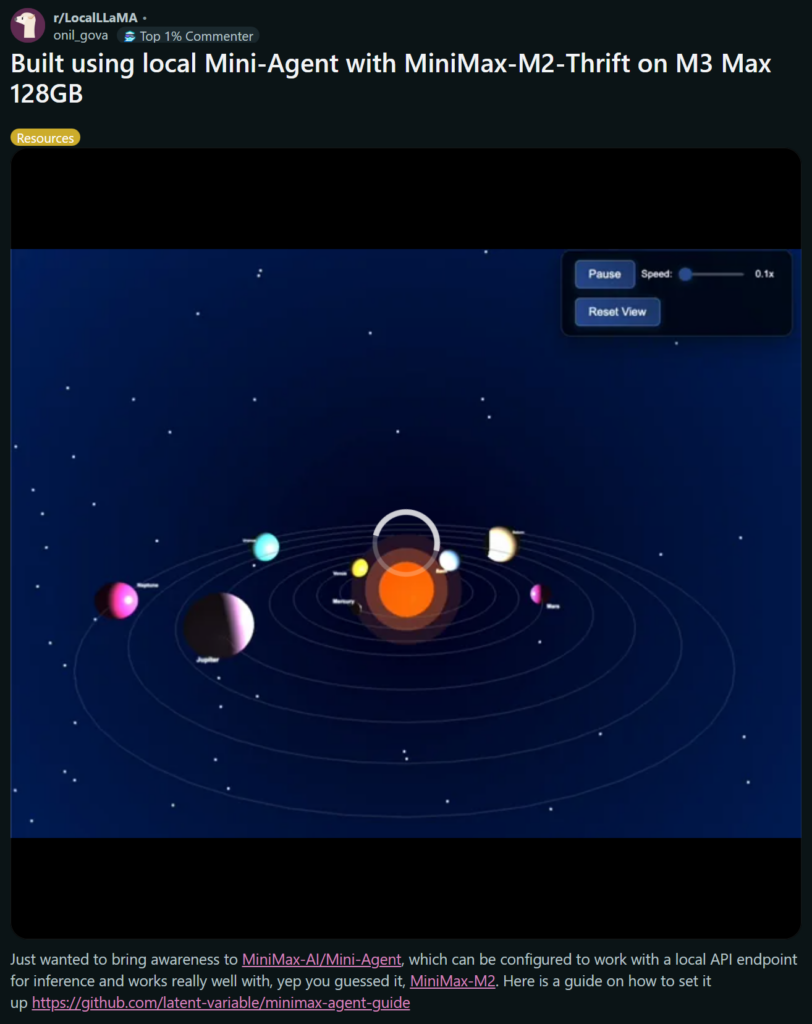
This one researcher with the username “onil_gova” who has absolutely no connection with us, posted on r/LocalLlama about what he was able to build with our THRIFT model running on a single MacBook Pro.
Further more, Cerebras themselves released REAP pruned models of MiniMax M2. So we dug in deeper and released a 55% pruned model which has now become the local State of the Art champion to the extent that in an AMA by the CEO and developer evangelist of MiniMax M2, a member asks them:
Their developer evangelist goes on to endorse our VibeStudio’s THIRFT pruned model if they are not able to run the original as it is just as good. With this we thought we’d hit the highest number of air guitars we will perform that day, but the best was yet to come.
Following these news media coverages:
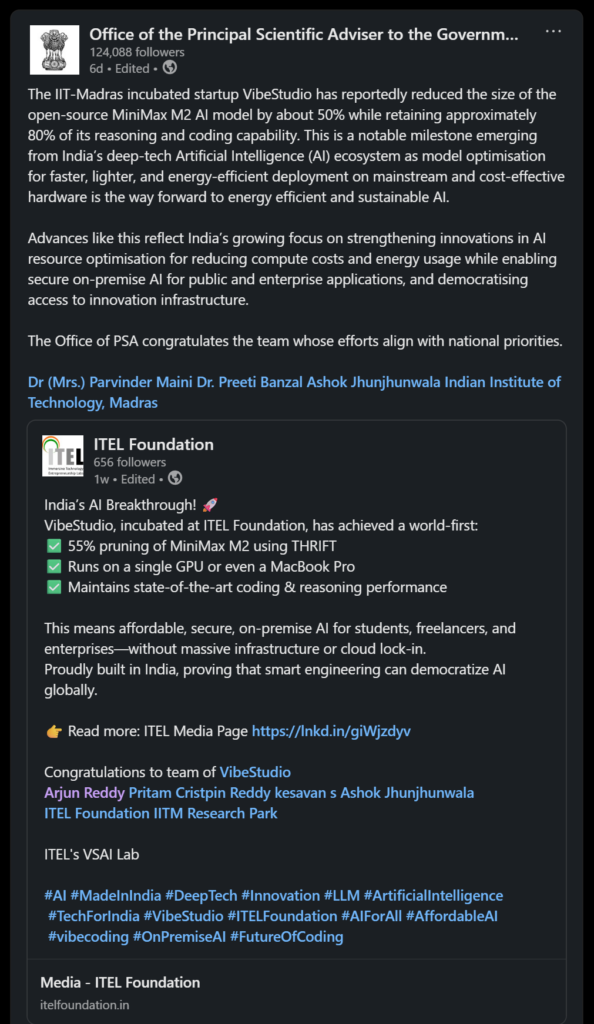
Office of the Principal Scientific Adviser to the Government of India – posted about us, nationalising our break through.
Aurite, that’s all good. How does this factor into the VibeStudio growth story? We have a local first thesis for our agentic suite. Making portable state of the art LLMs are how we get there. Even if we must use an external API our built in inference engine will use a smaller local model for drafting and thereby saving heaps for our customer. For our enterprise customers who wanted air-gapped SOTA performance, well, they were served perfectly.
If you’d like to use VibeStudio as a freelancer or with your team in your company, please drop us a line info@vibestud.io
Leave a Reply