We are happiest when our R&D leads to innovations help users save 50% off token cost. Here’s how we did it.

Say hello to building your entire application at almost half the cost of Cursor, Windsurf or Antigravity. This is not a marketing exaggeration. It comes from two engineering breakthroughs we created inside VibeStudio after months of practical work with real developers and real-world constraints. The first breakthrough is something we call Hive Mode inside the VibeStudio Agentic IDE. The second is our VS Code Extension that carries the same intelligence directly into the most widely used editor on the planet.
Hive Mode started as an internal experiment. We wanted to understand whether an IDE could become smart enough to pick the right model for each phase of a development workflow instead of blindly sending everything to one expensive frontier model. We observed that most coding tasks do not need the heaviest models. Many need a fast drafting model. Some need a refactoring model. Some need a model that understands your codebase intimately because it has already been running locally. Instead of putting the burden on developers to switch models manually, Hive Mode does this behind the scenes in a systematic and predictable manner. When the developer wants to override the model decisions, the IDE gives full control. When the developer wants to automate everything, the IDE handles it end to end. The result is a natural reduction in cost without a reduction in quality.
Alongside this, we built the VS Code Extension so that the same capability is available without asking developers to shift environments. Developers stay inside VS Code, but enjoy the full model routing and cost savings of Hive Mode. Local models, remote models, drafting models, task-specific models, and full frontier models work together inside a single workflow. The orchestration is invisible, but the savings are not. It cuts cloud API usage heavily and takes you closer to on-prem and local-first engineering.

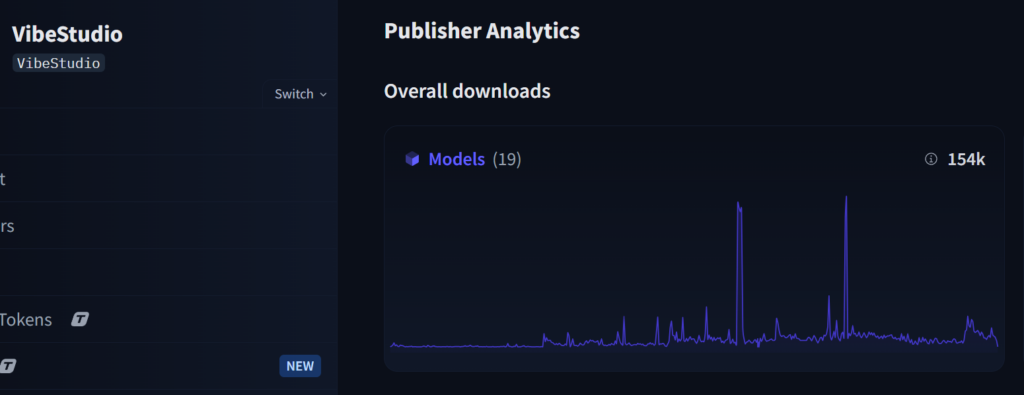
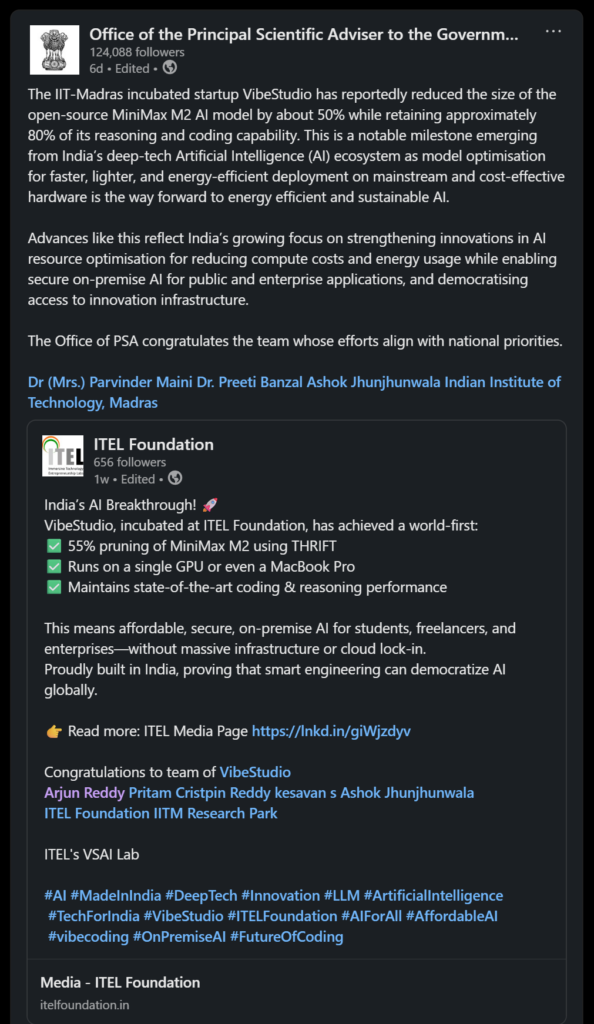
There is another innovation that significantly pushes the cost down. We call it ISD, Intelligent Speculative Decoding. This runs on our server infrastructure and accelerates responses while pushing efficiency even further. ISD works exceptionally well with the fine-tuned models we have been building and pruning in-house. The open-source community has already acknowledged this. The Hugging Face community and the r/LocalLlama community celebrated our pruned and fine-tuned models because they hit a rare, sweet spot. They are aggressively pruned while staying at frontier-level quality. We use these models as drafting models in Hive Mode. They do the heavy lifting early in the workflow before handing off to the full models only when absolutely required. This alone cuts a massive portion of the cost.
For B2B teams, VibeStudio can be deployed on-premise within ten days. It is free for the first six months for unlimited users so that teams can evaluate without pressure. For freelancers, we have a fifty percent discounted plan. The aim is simple. High quality engineering should not be a luxury product. It should be accessible, fast, local when needed and cost-efficient from day one.
Say hi to info@vibestud.io